CPAL
Motivation
之前尝试做 prompt learning 的几个方法(GoPT,DPLnet)都有一个共同问题:只关注了来自额外模态的单向的 prompt 传递到主干模型里,没有关注从主干返回的 prompt。CPAL 就是基于这个问题,关注了 RGB prompt 的影响,同时为了考虑模态的差异,引入了 LoRA。

Methods
主要有两个组件构成:MCP,GPM,并且适配器中的所有模块都采用了多模态设计。值得注意的是,作者选了近期的 VFM - internimage 作为基础模型。这里提一嘴,Internimage 其实是一个 CNN 变体模型,卷积层用的是 DCNv3(可变形卷积),并且也有考虑多尺度信息,单 RGB 训练任务表示如下:
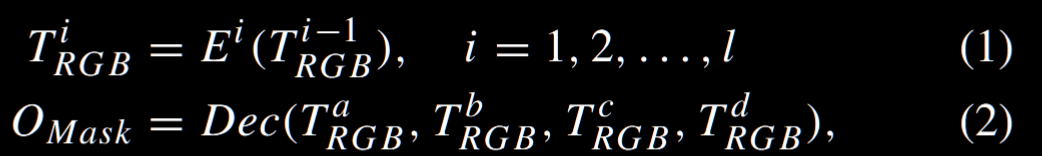
分成两阶段,第一阶段把来自不同模态的 token 丢进 MCP 里面生成双向的跨模态 prompt,然后做一个残差链接到编码器里:
第二部分,则是把两部分特征融合到一起,这里利用一个 GPM 模块达成这个目标,然后进行一个多尺度融合。
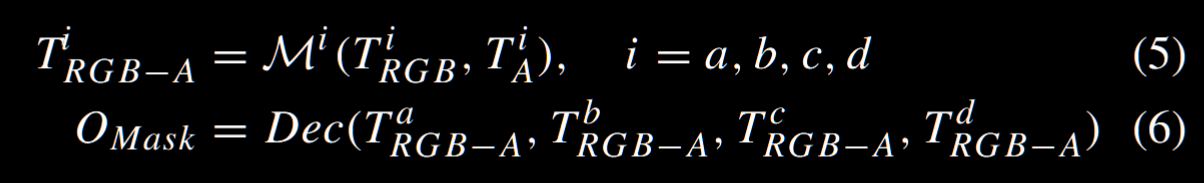
接下来讲一下两个模块,首先是 MCP 模块,这个模块设计的 motivation 是此前方法没有考虑不同模态的主次性,并且为了更好提升 VFM 里微调的效果,并且让适配器更好感知 RGB+X 的不同模态,设计了 MCP 模块分别集成到 DCNv3 里 和FFN 里:

具体实现如上,实际上就是在每个 LN 后面做残差链接,并且把 prompt 直接加到信息流里面,最后公式如下,注意这里是对两个模态都做了类似的工作,也是一些对称性的考虑了。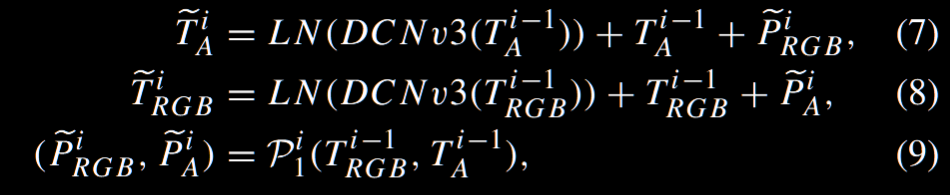
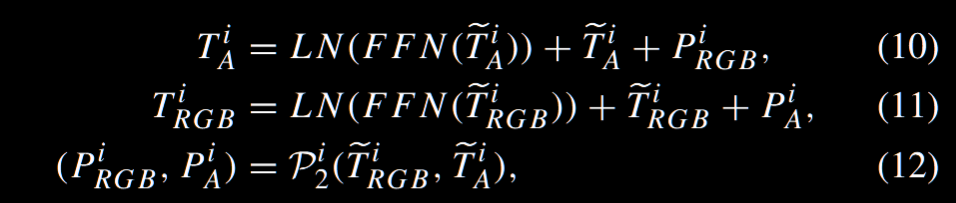
MCP 的具体结构如下:
每层得到具体信息实际上是怎么做?就是做了三次grouped conv(也是为了减少参数量),分别down,mid,up projection。
接下来看 GPM,GPM 这个实际上是为了过滤掉噪声并且有效让提示融合到交互的模态(因为如果直接做的话,会导致注意力更倾向于保留原有模态的信息)具体来说,首先把两部分的信息都经过1x1 卷积以及线性层之后,做一个交叉注意力得到一个关系矩阵。接下来用了一个遗忘门(来自 LSTM 里的)
其实整体的想法应该是让他做一个强制的融合?但是我不懂为什么这里不直接套一个其他方法的融合模块上去,因为他这里已经是把 prompt 都注入进去的情况。
最后一个创新点是引入了 LoRA 策略,这里的 LoRA 是考虑到之前的语义信息足够丰富,并且我们只在最后一层包含更多语义信息,所以只在最后一层的 DCNv3 用 LoRA。
| 层名称 | 功能 | 加入 LoRA 的目的 |
|---|---|---|
| Offset layer | 控制卷积核的采样偏移(决定采样位置) | 让模型能根据模态特征自动调整空间采样偏移,更灵活地捕获形变与跨模态差异。 |
| Mask layer | 控制每个采样点的权重(决定采样强度) | 通过低秩调整增强模型对不同模态(RGB/X)的选择性注意力。 |