DPLnet
Motivation
为了提出一种训练高效,部署友好的高效微调分割方式,作者把 NLP 里的提示学习的想法引入了视觉任务中,作为高效微调的一种手段。并且考虑需要同时处理模态融合和冻结主干网络中的特征适配,作者就提出了 DPLNet,一种双提示学习网络。作者引入了两个模块:MPG 和 MFA。MPG 是吧重要的辅助模态特征和 RGB 特征相融合,生成互补的多模态特征提示。同时 MFA 在每层里面,用独立的交叉注意力模块来融合。
Method
我们考虑对于原本 $T_{RGB}$ 模型的每一层 $Z^i$,以及每个编码模块 $B_i$,首先对于输入层,我们依然使用原本 $T_{RGB}$ 学习冻结的 patch embedding 来获取 RGB 信息,而对于多模态的信息则用另外的可学习的 patch embedding.接下来,每层使用一组 MPG 来学习多模态提示,然后通过残差链接添加到原始的 RGB (也就是注入了prompt的特征),用于 encoder。而学习 prompt 的过程可以表示为:
$$
Z^{i-1} = Z^{i-1}{RGB}+P^i,P^i=MPG(Z{RGB}^{i-1},P^{i-1})
$$
这里的 $P_i$ 代表的就是由 MPG 生成的多模态提示,对于 $B_i$ 的每个注意力层,生成一组可学习的提示标记 $H_i^k$ ,这个 $H^i_k$ 用于在下面的 MFA 里生成 KV,
先讲一下 MPG 模块:

对于编码模块 $B_{i-1}$ 生成的特征 $Z_{i-1}$ 和提示 $P_{i-1}$,首先通过一个 3x3 卷积层生成 $\hat{P}_{i-1}$,为了融合多个尺度的信息并实现特征适配,我们在通道维度上对不同模态特征下采样实现融合,也就是: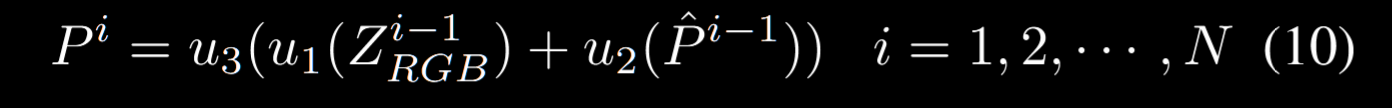
这里 $u_1,u_2$ 是两个降特征维用的投影层,$u_3$ 是上采样特征维的层。不过有个问题,这里为啥直接加了?shortcut吗。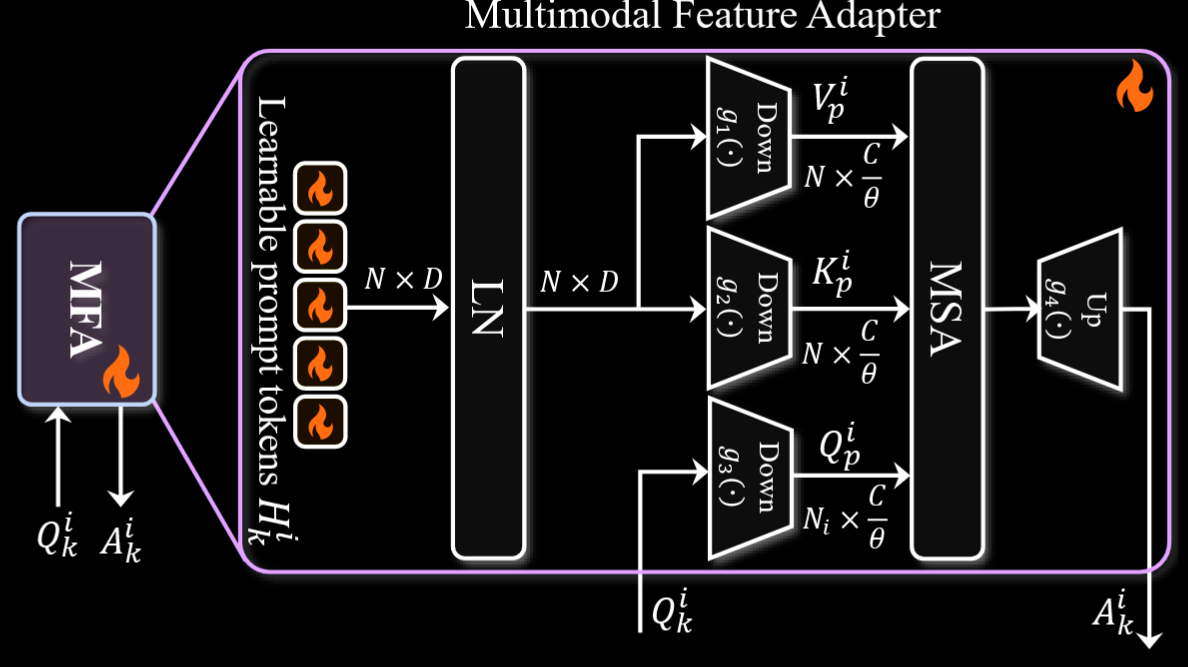
接下来说 MFA,这个的想法其实也是有点类似 Lora,因为预训练模型处于比较低的内在维度,使用一个线性投影层把 $Q$ 投影成 $Q_{p}^i$ ,同时从刚才的 $H_k^i$ 里 LN 后下采样出 $K,V$ 进行类似的降维操作(注意这里都是用归一化),然后再返回原本有的 $A_k^i$.其实本质上就是在prompt的低秩空间做了一个注意力,然后把这部分的信息直接相加到主网络的多头自注意力中。