GoPT
Motivation
同样是从 NLP 任务中获取对于多模态微调 RGB 模型的灵感,此前的方法有问题在于:
- 跨模态之间的问题:不同成像机制的模态的异质差距,需要对齐。
- 对于信息的不平衡:基于聚合的融合方法经常忽略模态内部本身的信息。
所以作者提出了 GoPT,也就是显式地对上下文语义分组,生成统一的 Prompt 来做提示调优的任务。
Method
我们的 prompt 方式可以看作是对于每个层的最终特征 $f^{l,i}$,有 RGB 特征 $f^{l,i}{RGB}$,利用 GoPT 生成 prompt token $P^{l,i}$,最后就是:
$$
f^{l,i} = f^{l,i}{rgb} * P^{l,i}
$$
为了实现, 有两个模块 CUP 和 ACP。CUP 这个模块的想法是把每个块的特征给按类别分组,我们引入 class token $c_{m}^{l,j}$,为了获取每个 patch feature 的分类,我们选择 concat 到一起之后做一个自注意力:
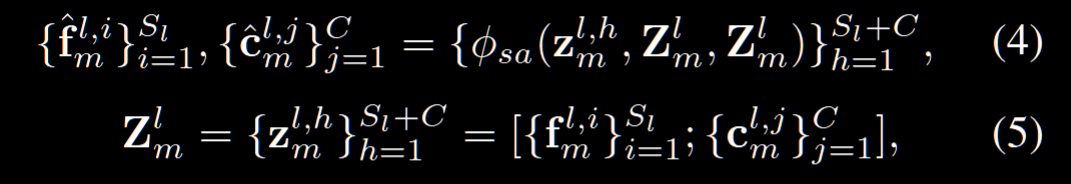
接下来,我们需要找到每个 token 对应最相关的类,但是要注意我们这里用的是 Gumbel-Softmax,因为取 max 的话会导致离散,梯度传不回去。所以用 Gumbel-Softmax:
Gumbel-Softmax:
其实就是让取最值的这个过程变得可微,本质上也是取 max 的一个东西,但是引入了概率,所以不会很直接的取max
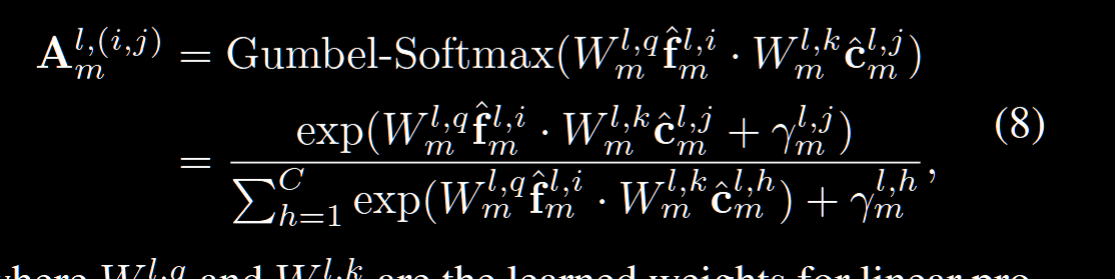
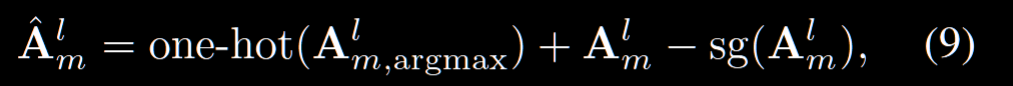
这里称为取 hard assignment,其实也有 soft assignments,也就是用 $A^l_m$
2) ACP:Alignment-Induced Cross-modal Prompter(把类提示对齐注入 RGB)
输入:RGB tokens $F^{,l}{\text{rgb}}$ 与来自 CUP 的类提示 $P^{,l}{m}$。
用 $P^{,l}_{m}$ 作为 K/V,让每个 RGB token 去“查阅”这些类提示(跨注意力)以抽取跨模态的关键模式:
$$
H^{,l,m}{\text{rgb}}(i,\cdot) ;=;
\mathrm{softmax}!\Big(
\frac{(W_q f^{,l,i}{\text{rgb}}),(W_k P^{,l}{m})^\top}{\sqrt{d}}
\Big),(W_v P^{,l}{m})
$$
得到的 $H^{,l,m}{\text{rgb}}$ 再经一个线性/门控整合成对齐感知提示 $P^{,l}{\text{rgb},m}$,并对 RGB 流进行乘法门控(与上式总框架一致):
$$
f^{,l,i}{\text{rgb}} \leftarrow f^{,l,i}{\text{rgb}} ;*; g!\big(P^{,l}_{\text{rgb},m}\big)
$$
若有多路辅助模态 ${m}$,可以串行或并行注入,门控可做乘积/加权组合(实现层面常用并行 + 逐通道/逐 token 门控)。
逐层继承:$C^{,l{+}1}{m} \leftarrow P^{,l}{m}$。也就是下一层的“类原型”直接沿用上一层学到的类提示,使跨层、跨模态的统计逐步稳定。
- Soft:训练更稳、对噪声/弱标注友好,但提示可能被“摊薄”,语义边界更模糊。
- Hard(直通):提示更纯、更判别,对后续乘法门控更有利;训练初期可用温度退火从 soft 过渡到 hard。
- 实务上常见策略:前期 soft,后期 hard;或仅对高置信样本使用 hard。