HRNet学习笔记
学长推荐(4/20)
以后吃 brunch 不要吃猪脚饭和热卤拌饭,到工位直接昏迷两小时了
HRnet 是打通多个视觉任务的 backbone,虽然最开始是以人体姿态识别为开始,但是后来发现 HRnet 实际上是很通用的。
Motivation
在人体姿态识别的任务里,经常会需要生成高分辨率的 heatmap.而在之前的工作里,都是通过先 downscaling,再 upsampling 这样的思路来进行的。总体来说都是这样让不同分辨率进行串联: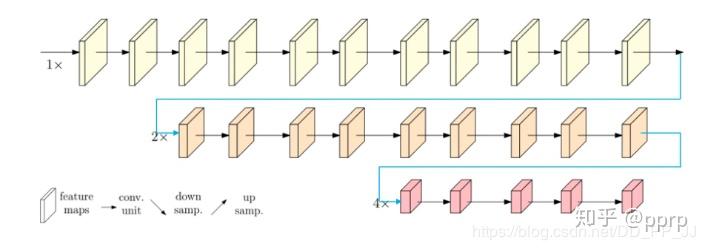
HRnet 的动机就是考虑让不同分辨率的 feature map 进行并联,并且添加交互: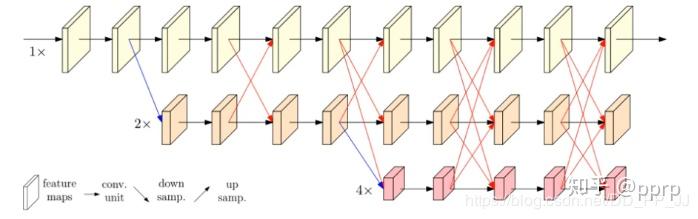
Method
在并联的基础上,同时增加了一个 Fusion 的过程,具体来说是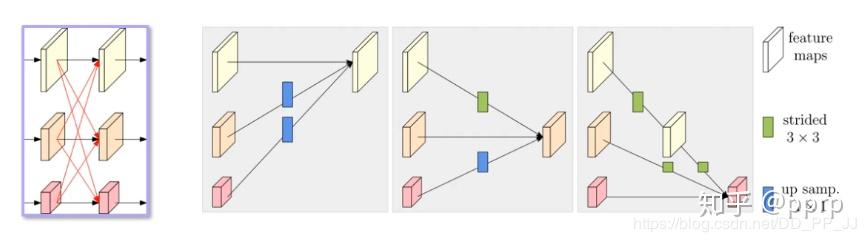
- 同分辨率的层直接复制
- 需要升分辨率的用双线性插值 + 1x1 卷积统一通道
- 降分辨率的使用带有步幅的 3x3 卷积
- 把三个分辨率相加融合。
如果有四个分支的化,HRnet 给出了几种方式:
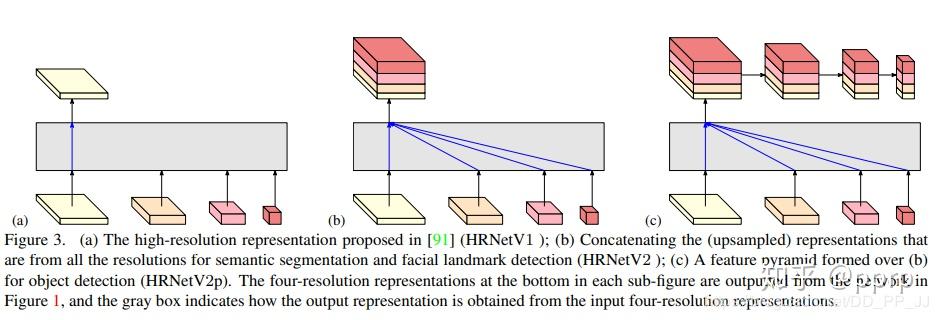
- 使用分辨率最高的特征图,适用于关键点检测或者图像分类(v1)
- 把所有特征图融合,适用于语义分割(v2)
- 使用特征金字塔,适用于目标检测网络(v2p)
通过以上方式,HRnet 在整个网络中都保留了高分辨率的表征,也就是图中 x1 的分支。
Experiment
HRnet 在多个任务中都表现良好,证明了自己的潜力:
姿态识别
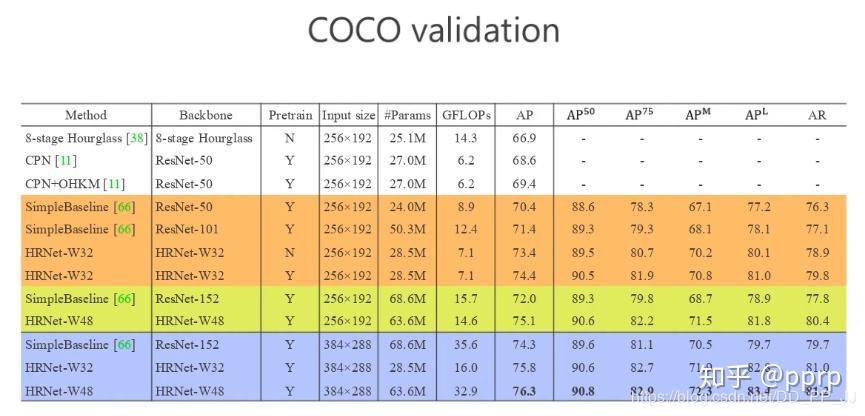
在参数和计算量不增加的情况下,要比其他同类网络效果好很多。
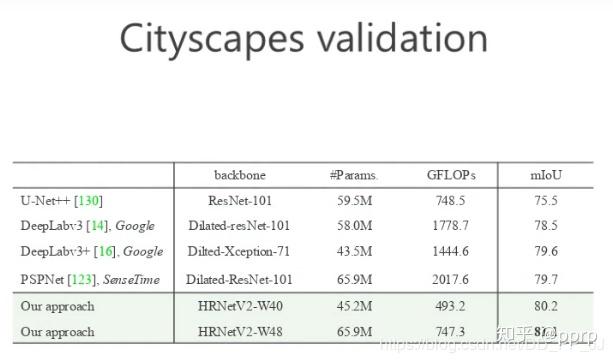
语义分割
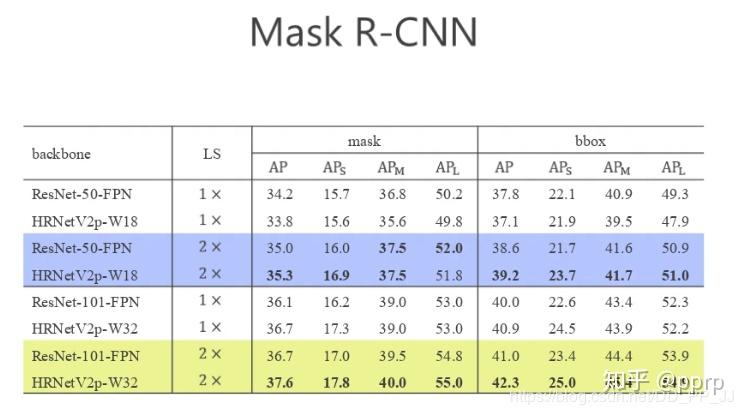
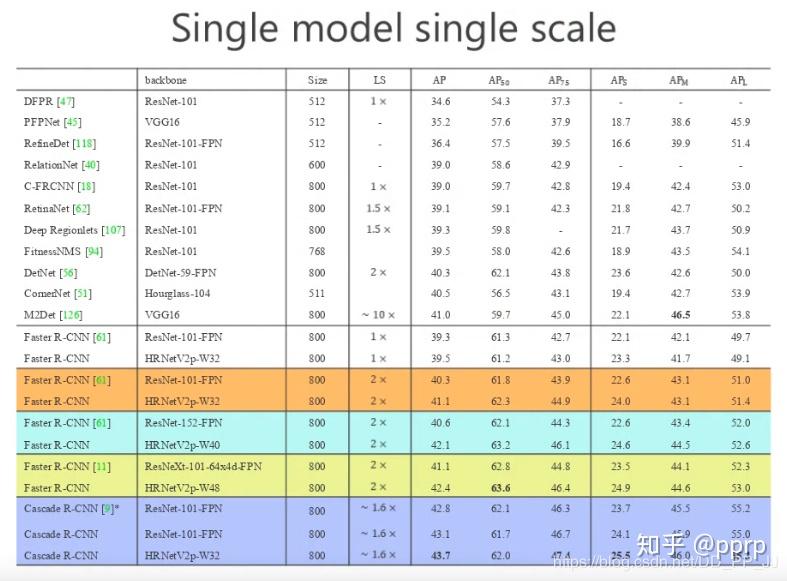
目标检测
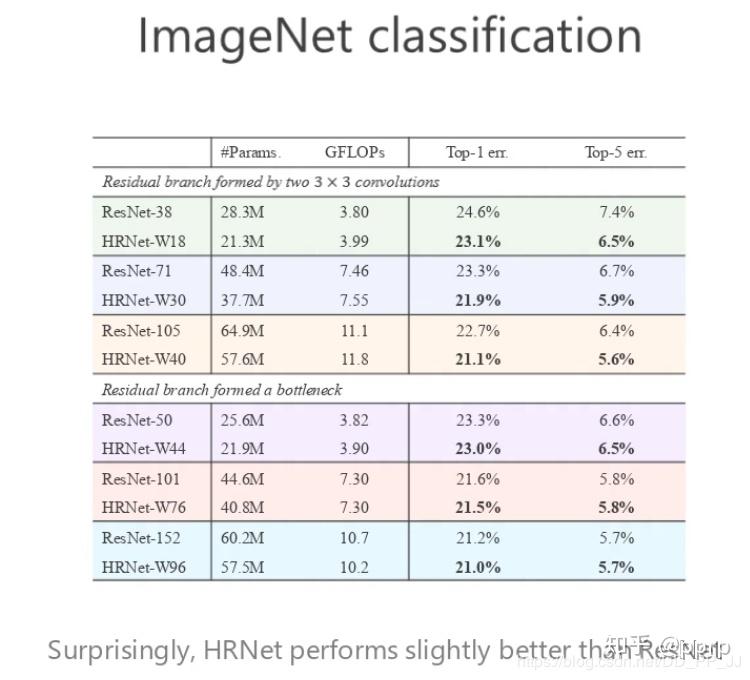
分类任务
HRNet学习笔记