Multimodal Token Fusion for Vision Transformers
此前对于多模态信息的处理,作者认为这样的做法没有考虑对齐关系,会把注意力分散并且没法达到最好的效果。但如果考虑了对齐感知的融合,那么又可能会改变原本在单个 RGB 模态下获得的结构,导致削弱了预训练阶段学到的东西。所以作者提出了 tokenfusion:自适应且有效融合多个单模态的 transformer.
Method
basic idea:对多个单模态的 transformer 进行剪枝,然后用来自其他模态的投影对齐特征替换每个被剪枝的单元。
具体来说,我们用一个评分函数 $s^l(e^l) = \text{MLP}(e^l) \in[0,1]$ 对每一层的每个 token 进行评分,动态预测 $l$ 层和模态 $m$ 下标记的重要性。所以我们改变一下这里的 MSA 公式为:
$$
\hat{e}^l_M = \text{MSA}(\text{LN}(e^l_m)·s^l(e^l_m))
$$
对于模态 $m$ 的 loss,我们考虑在 $s^l(e^l)$ 上添加一个逐个 token 的剪枝 loss,所以整体 loss 就是:
$$
L = \sum\limits_{m=1}^M (L_m + \lambda \sum\limits_{l=1}^L |s^l(e^l_m)|)
$$
这里 $L_m$ 是代表的每个任务特定的 loss,后面实际上是相当于取了一个稀疏的 L1范数。
接下来是重要的过程:用来自其他模态的标记投影代替不重要的标记,这部分内容同样是动态的,在每一层之前执行标记替换,所以 $e^l_m$ 被重新表述为
$$
e_l^m = e_l^m \cdot I_{s_l(e_l^m) \ge \theta} +
Proj^M_{m’}(e_l^{m’}) \cdot I_{s_l(e_l^m) < \theta}
$$
其实就是考虑,如果这个模态的 token 分数 $\geq θ$(这里 θ 在实验固定取 $10^{-2}$,但是实际上可以视为一个超参数) 那么就保持原有的 token,否则则用其他模态的 token 投影来替换他。如果这里只有两个模态,那么 $m^{‘}$ 就是另一个模态,如果有 > 2 个模态的话,我们考虑:
对于想同纬度:论文认为,不管是生成还是回归任务,同质的视觉模态通常是和像素对齐的, 也就是相同像素应该共享相同标签。因为像素对齐,也就是说让多模态共享同一套 Transformer 的 MSA 和 MLP 参数,但每个模态用各自的 LayerNorm,以避免不同模态统计分布差异彼此干扰。那么对于 $M>2$ 个模态,我们可以把上面的式子更改成: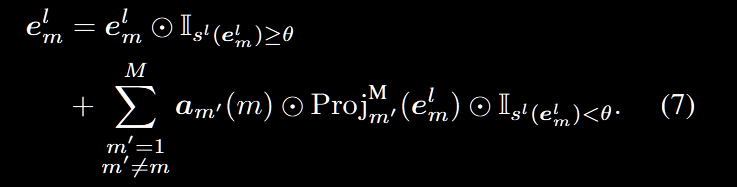
对所有模态应用Token的剪枝,具体来说,就是把每个模态的 $N$ 个 token 分配到 $M-1$ 个组里面,然后如果有一个 token 要替换,就让他被绑定到的组里的模态来替换。
这两段给我看晕了,但是代码还可以:
1 | class TokenExchange(nn.Module): |
其实就是一个mask的过程?但是对于 > 2 模态的我没有看到相关代码。
为了实现不同模态之间的融合,引入了 RPA 模块,这个模块的想法是保留 positional embedding.本质上是做一个残差链接,就是把每个图象的embedding信息在每个 token fusion完都留一份,而这部分 PE 是冻结的,也就是说只有最开始的 PE 能有梯度更新。也就是即使原始标记替换了,那么我仍然保留原来的 PE,相当于作为一个锚点。
另外,对于不同维度的模态,作者这里选用了投影机制,也就是利用相机参数得到 3D 信息在二维的投影,也就是

以及这里的投影函数 $h$ 则是直接利用一个 MLP 来做的。
Multimodal Token Fusion for Vision Transformers
https://doubeecat.cn/post/Multimodal Token Fusion for Vision Transformers/