OmniSegmentor
Motivation
之前的工作的缺陷在于:
- 做多模态融合的时候可能只关注于少数模态,比如 Dformer,只采用了一种(RGB-D)额外模态进行操作
- 需要大规模数据集满足训练需求
所以作者承接 Dformer 的工作,提出了一个大规模多模态数据集 ImageNeXt,为了更好地适应多模态数据,在预训练阶段,提出了一种方法,不再在每次迭代中同时输入所有类型的模态数据,而是采用分批输入的方式,把 RGB 数据和其他随机选择的模态数据输入进模型然后对齐。这就是 OmniSegmentor。
Method
关于 ImageNeXt 这个数据集,它尝试涵盖了尽可能多的主流视觉模态,有D,T,LiDAR,Event 几种。每种都对应了一种多模态信息的估计方法。
现在基于 ImageNeXt 进行训练,但是作者发现,把所有模态统一丢进去训不太好收敛,并且测出来效果也很差,所以作者在预训练阶段采用的方法是以 RGB 和随机选择的补充模态作为输入。作者在这里直接选用了 Dformer 的框架,符合直觉的是这样也可以让方法work。这部分里不同模态的编码是一样的
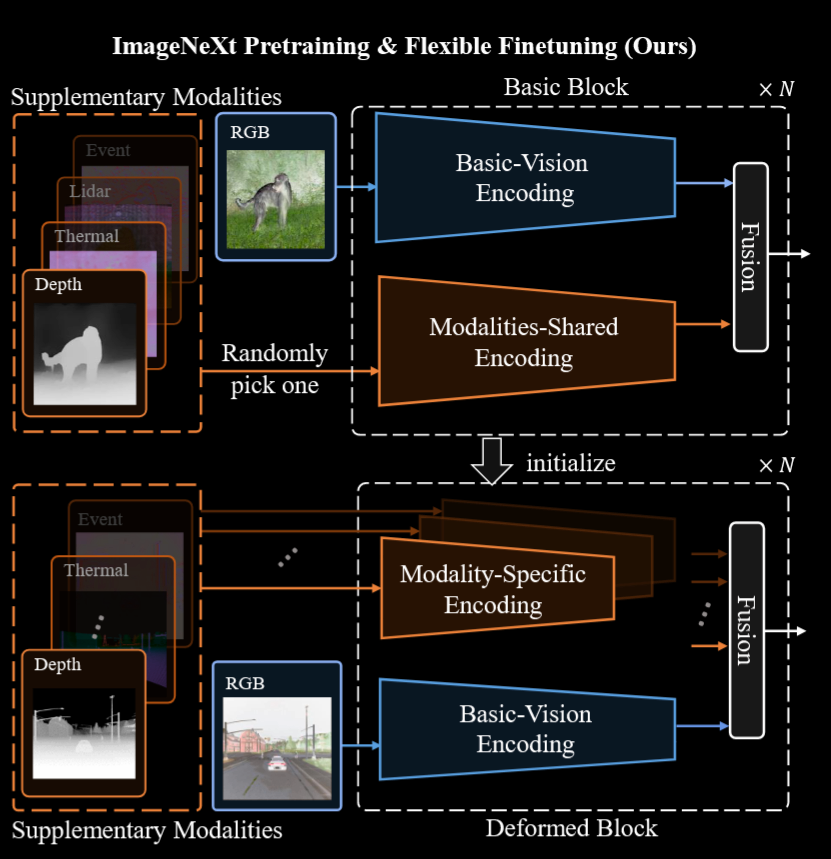
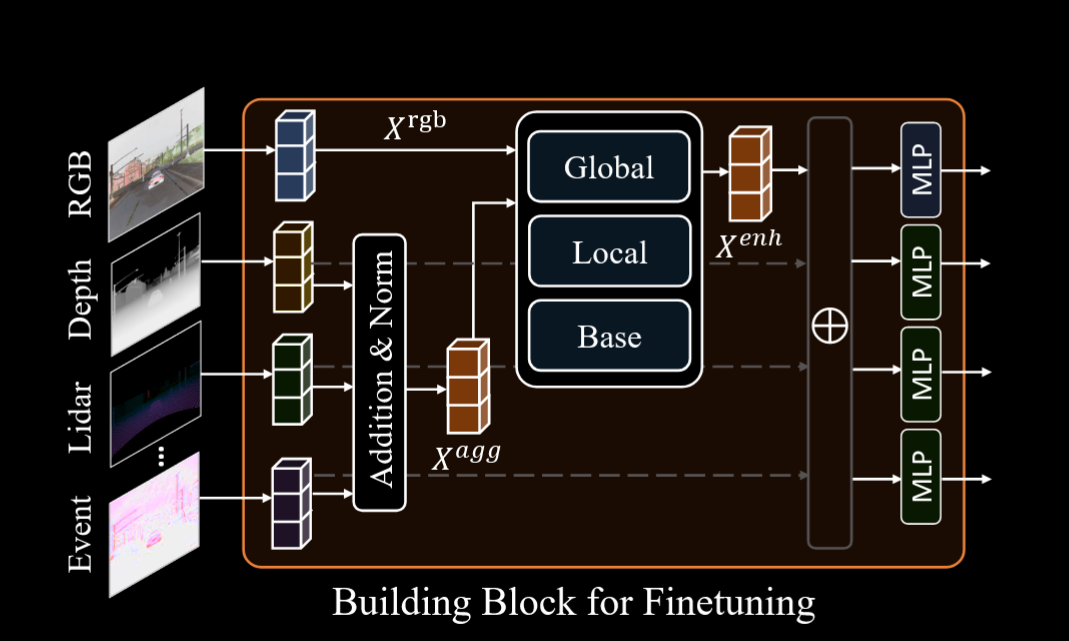
对于下游任务来说,作者同样提出了一种高效的微调策略:首先考虑我们需要用所有的额外模态实现稳健的分割方案,那么就是需要我们对于每个模态使用独特的特异性编码。在实际的下游任务里,由于使用的模态不一定一样(个数,种类等),所以对微调的任务每个使用独特的 stem 层。多个模态特征通过简单的加和和 LayerNorm 得到特征 $X_{agg}$,再和 RGB 特征直接相加得到 $X_{enh}$ 丢进分割头。消融实验证明简单的相加加正则化就能达成很好的效果。
OmniSegmentor