Rein
Motivation:随着更多强大的预训练视觉模型的推出,作者考虑选用一种方法完成更小更强的 DGSS 任务。同时注意到 DGSS 这部分任务的问题在于数据集规模小,如果直接进行微调会导致泛化能力受限(直观理解大概是学不到东西?)这篇文章写的 rein 这个方法就是鲁棒地进行高效率的微调,通过更少的可训练参数驱动更强的视觉基础模型。
Method
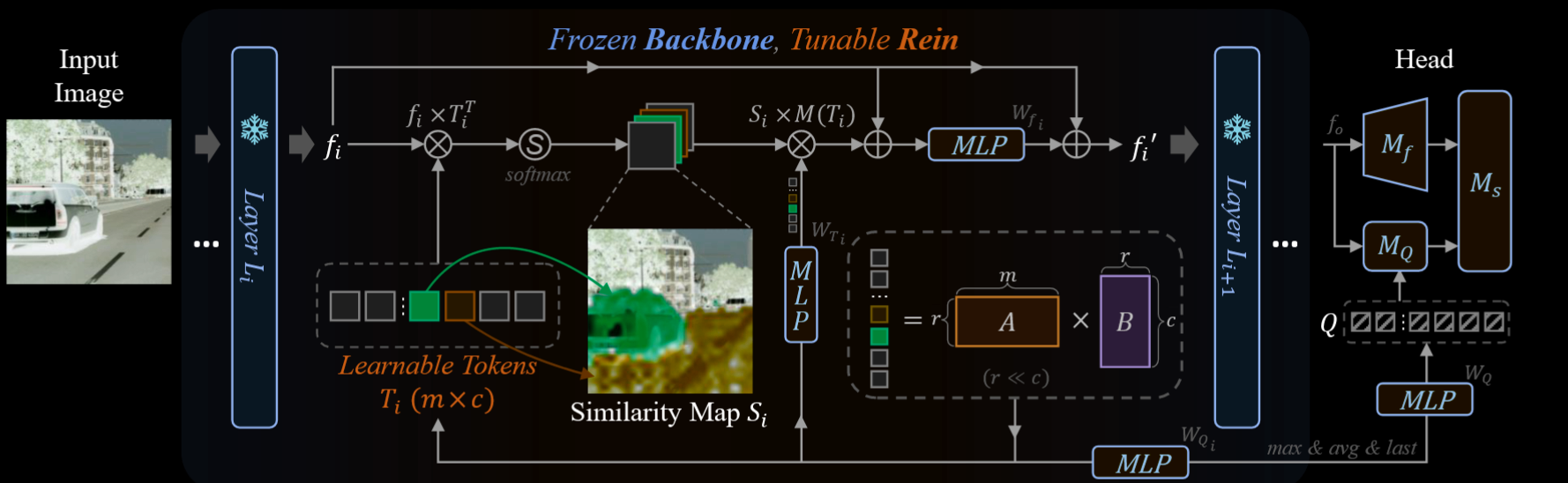
想法是在 VFM backbone 的各层之间嵌入一种名为“Rein”的机制。Rein能够主动地对每一层的特征图进行细化,并将其传递到下一层。方法专注于优化 VFM 每一层输出特征图,也就是对于 $L_i$生成的特征 $f_i$ 我们需要进行如下优化:
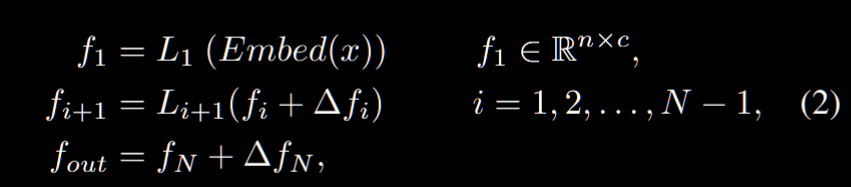
也就是我们对 $\Delta f_i = Rein(f_i)$ 做优化,而中间的 $L_i$ 实际上都是冻结的,我们只对特征图有做法。理想的 $\Delta f_i$ 有助于 VFM 拟合数据集和目标场景的差异 + 预训练和微调任务的差异。Rein 从可学习的标记 $T_i$ 入手,然后把序列 $T_i$ 随机初始化,用点积生成相似度图 $S_i$ 用于捕捉 $f_i$ 中的特征向量和 $T$ 的关系,当然这也是可以 softmax 的:
$$
S_i = Softmax(\frac{f_i \times T_i^T}{\sqrt{c}})
$$
然后我们用一个 MLP 来估计 $\Delta \bar{f_i}$ 也就是利用 $S_i$ 多做一个 $W_{T_i},b_{T_i}$:
$$
\Delta \bar{f_i} = S_i(:,2:m)\times[T_i(2:m)\times W_{T_i} + B_{T_i}]
$$
注意这里我们不选 $S_i,T_i$ 的第一行第一列,这里的考虑是模型把第一个标记留给吸收权重用,但是 在计算的时候直接丢掉,让剩余 token 的增量接近 0,避免一些坏的特征改动(感觉像是一个trick?不太确定查一下)。我们的优化目标就是优化 $\Delta f_i = (\Delta \bar{f_i} + f_i)\times W_{f_i}+b_{f_i}$
读着读着突然发现这里其实就是对 $f_i$ 做了一个交叉注意力,就是看图把最后公式展开就是 $\Delta \bar{f_i} = CrossAttention(f_i,T_i,MLP(T_i))$ 也就是我们以 $T$ 作为 KV,然后把 $f_i$ 当作 Q。
接下来 $T_i$ 学到了一堆信息,然后我们要把 $T_i$ 给丢到解码头里面,也就是生成一个 $Q_i$ 和 $M_Q$ 进行交互。具体来说,我们通过 $Q_i = T_i \times W_{Q_i} + b_{Q_i}$ 得到每一层的 $Q_i$,最后我们取 $Q_{max},Q_{avg},Q_N$ concat 起来,然后做一个 MLP,丢给解码头的 $Q$ 进行交互。注意到我们在上面实际上用了很多的 MLP,论文提出了,对于 $T,f,Q$ 他们的 MLP 是共用的,所以最后实际上只是新增了三个 MLP 层的 W,b 矩阵罢了。同时为了减少参数量,做一个低矢分解,也就是让 $T_i = A_i \times B_i$。