ResNet学习笔记
学长推荐 (1/20)
Motivation
经验表明,网络深度和提取的特征模式复杂程度理论上成正比,但是实际上,网络深度越高,网络准确度会出现饱和甚至下降。而由于 BN 的存在,也并不是因为梯度消失 / 爆炸的问题。
Kaiming 做了一个实验,也就是在网络里叠加了一层 $G(x)$,如果令 $G(x) = x$ 的话,那么至少不会比原本的网络更差,但是实则不然。所以他推测 $G(x)$ 如果是一般情况下,并不能很好拟合 $G(x) = x$ 这种函数,那么解决办法就应该是把 $x$ 直接加进去,所以就有了 ResNet.
Main methods
我们考虑一个最简单的方式加入 $x$ (下面都称为 identity 函数),记原始特征是 $H(x)$,那么就是:$H(x) = F(x) + x$ 学习的原始特征就是 $F(x) + x$。这个道理在于,如果 $F(x) = 0$ 那么实际上等价于 identity 函数,也不会降低性能。实际上 $F(x) \not= 0$ 也就会让后面的层在基础上学习到新的特征,拥有更好的性能。
ResNet 在设计上参考了 VGGnet,但是更深并且加入了残差设计,使用了 stride = 2 的卷积做下采样,然后用 avg pool 代替了两个全连接层,避免过拟合同时减少了参数量。并且注意,ResNet 使用了 BN 而不是 dropout.
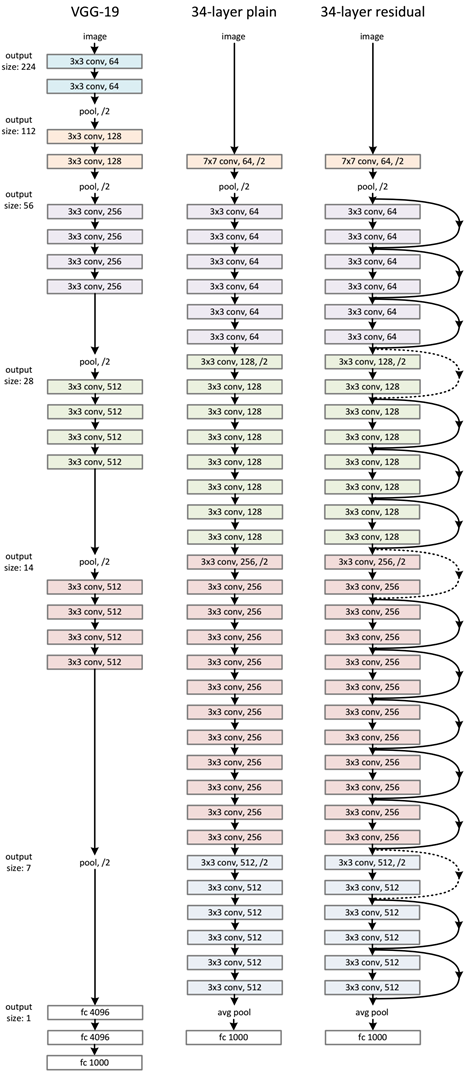
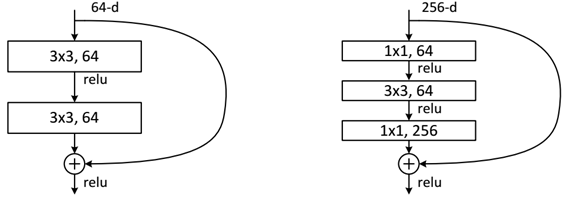
ResNet 里面采用了两种残差单元,一种浅层网络的是用两个 $3\times 3$ 的卷积层堆叠成。结构简单直观。第二种是瓶颈残差块,它由三层卷积构成,顺序是 $1 \times 1$ 卷积、$3 \times 3$ 卷积、再接一个 $1 \times 1$ 卷积。
那么怎么实现短路链接?因为输入和输出很多时候维度不一样,有两种办法:
- Projection Shortcuts : 对输入 $x$ 进行线性变换,维度和 $F(x)$ 保持一致,也就是用一个 $1\times 1$ 的卷积核卷一下。
- Identity : 使用 zero-padding,这就不会增加额外的参数了.
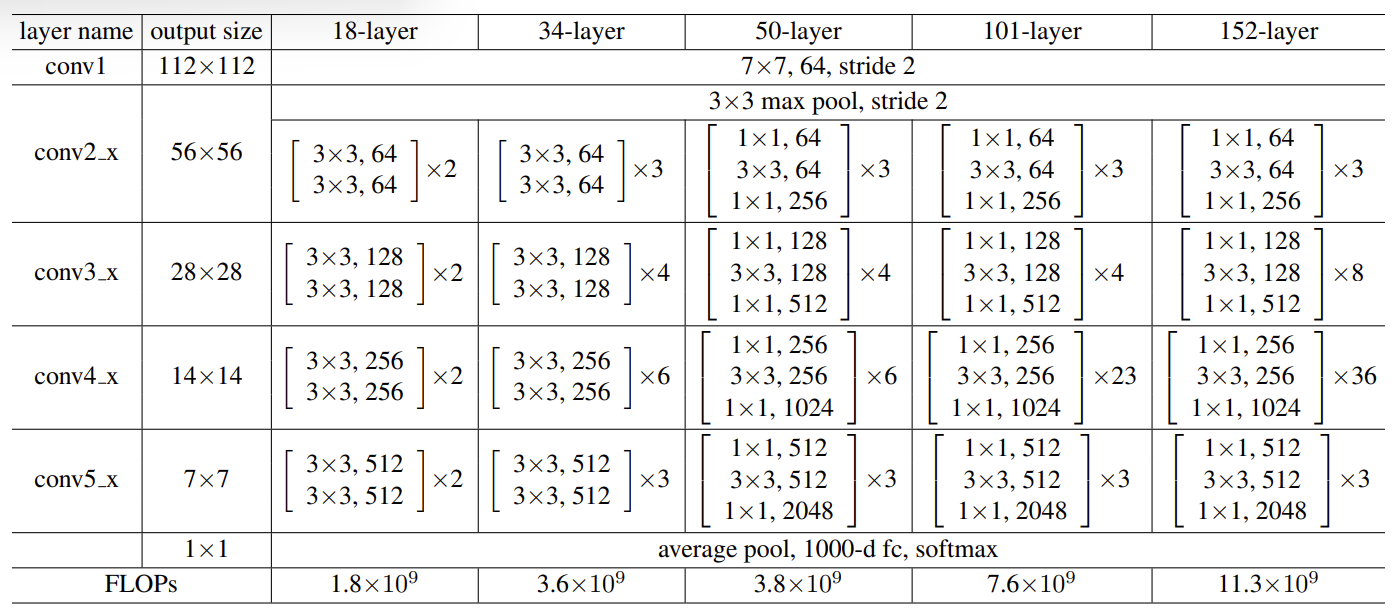
Experiments
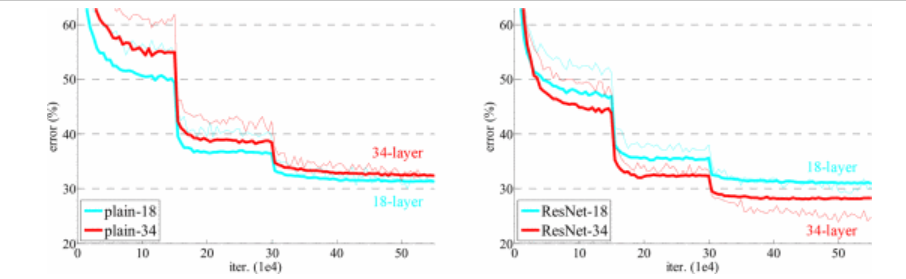
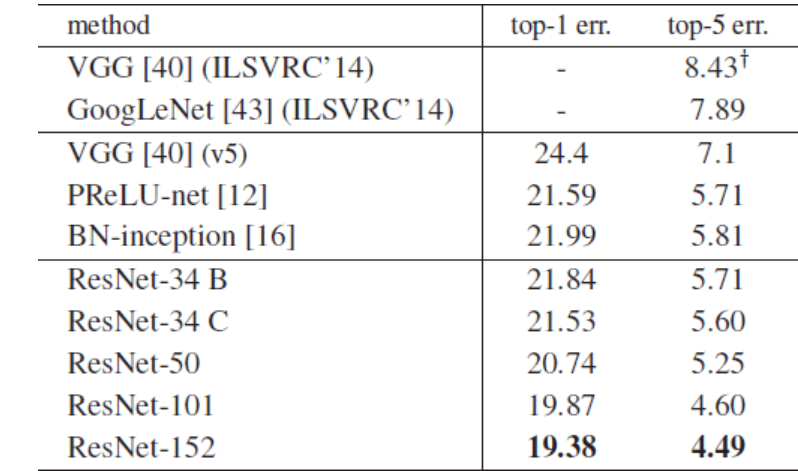
ResNet 在 ImageNet 上获得了 2015 年的冠军,打赢了人类。并且在训练上展现出了具有实际意义的差距
ResNet学习笔记