SETR
学长推荐 (11/20)
Motivation
之前大部分研究方向都基于 FCN 范式的 Decoder - Encoder 结构,也就是先把一个图像 downscale 来提取出高维度的信息,然后再 upscaling 补充细节信息。但是这样有几个问题:
- 实际感受野远小于理论感受野
- 下采样太多会导致小目标细节信息丢失
- 参数量增大
之前的想法有用改造卷积(比如 PSPnet,deeplab 等)也有用 attention 机制的,但是换汤不换药。ViT 的出现给作者带来了新的想法:
Method
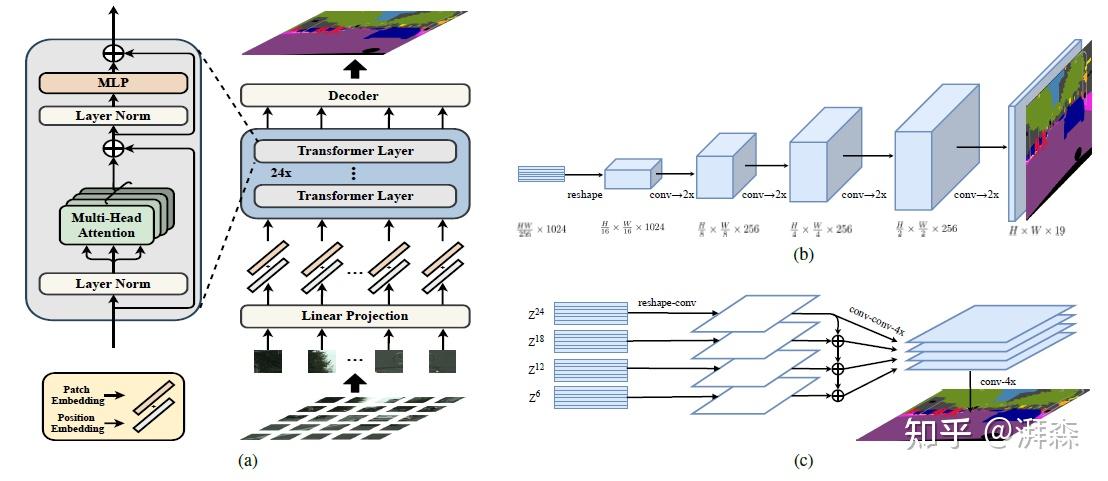
encoder 部分,按照 $16\times 16$ 的小块划分,然后给每个位置学习一个特定的嵌入 $p_i$,在用一个线性投影函数(patch embeddings) $e_i$ 形成最终的一维序列 $E = {e_i + p_i}$ ,学习了对应的位置信息。这边我们需要注意他的patch embedding和position embedding,这部分实际上是和 ViT 完全一样的,所以允许我们直接套用之前的权重。这也带来一个问题:我们知道 Transformer 是没有多层次感受能力的,不像 CNN,CNN 是可以有多个层级的感受特征的。所以需要后面的 decoder 来分层次合并特征。
Decoder 部分:作者给了三种结构:
- 第一种是 conv + BN + ReLU + conv,然后双线性上采样回原图分辨率。
- 第二种是渐进式上采样,参考图 (b),也就是每次上采样 2 倍,参考 U-net 的 Decoder
- 第三种是类似金字塔的融合结构,每隔 6 层抽取一个输出特征,然后 reshape 成 $\frac{1}{16}$ 的尺寸,经过一个 3 层的网络+4 倍双线性上采样操作,最后自顶向下逐层融合,按照通道维度进行拼接,然后直接 4 倍双线性上采样回去。这边是因为他要多个层次的信息。
Experiments
数据集: Cityscapes,ADE20k,PASCAL Context
类似 PSPnet,作者同样引入了辅助损失,研究了一下,辅助损失这个东西其实就是为了改善深层次网络中梯度消失的问题,并且提供中间的监督,让网络变得更加清晰和结构化。
作者直接把 ViT 训练出来的权重用于 SETR 的编码器进行权重初始化。