分割领域泛读(FCN,Unet)
学长推荐(7~9/20)
FCN
FCN 的想法很简单,其实说起来就一句话:把 VGG 最后的全连接层换成卷积层,最后输出的就是一个尺寸等于原图,但是每个点带有一个 label 的分割完的图片。
FCN 充分考虑了不同尺度的特征,有 $\frac{1}{32},\frac{1}{16},\frac{1}{8}$ 的特征上采样之后融合在一起。但是也是因为直接上采样导致的对像素之间的关系考虑的不够准确,细节不够敏感。
Unet
UNet 引入的两个很重要的结构:U 形网络结构和 skip connection.
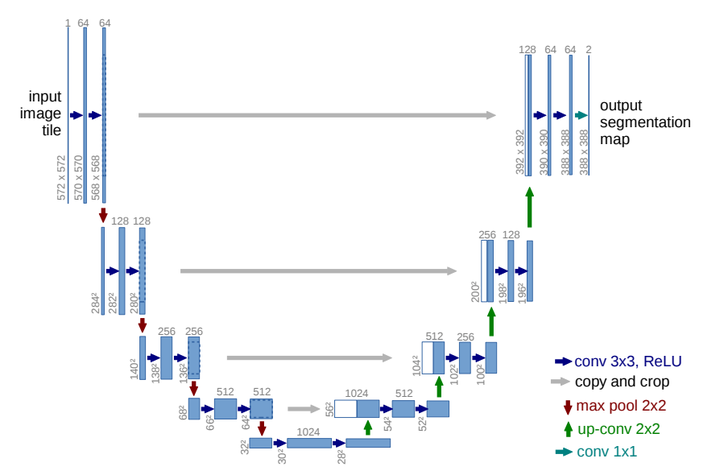
左边这部分实际上是一个通过卷积层一直 downscaling 的过程,也就称之为 encoder。右边是一层层 upscaling 的过程,并且 concat 左边juanjiceng 的过程(也就是 skip connection)称之为 decoder.
concat 的过程其实很简单,假设我们现在的卷积层尺寸是 $256 \times 256 \times 3$ 的尺寸,那么 concat 上左边尺寸为 $256\times 256 \times 4$ 的卷积层之后就是 $256\times 256\times 7$,相当于把两个层直接的叠加在一起。对于 feature map 也是一样的,如果尺寸不一样,Unet 的处理方法是对尺寸比较小的层进行 padding.
Unet 的每一个分辨率,都使用了两次卷积,这是因为进行两次尺度较小的卷积可以达到和一次尺度较大的卷积的感受野程度相当。而且这样相当于多用了一次 ReLU,也就更能捕捉到非线性信息。下采样部分用的是 maxpooling,可以很方便地把卷积层进行下采样。
对于 up-conv 部分,上采样部分选用了线性双插值。并且每次记得 concat 上之前的。“总而言之,这类跳跃连接背后的设计动机在于,它们从第一层到最后一层具有无中断的梯度流动,从而解决了梯度消失的问题。连接型跳跃连接提供了一种可选机制,以确保来自早期层的相同维度特征可以重复使用,并且得到了广泛应用。”也就是好训练
1 | class Up(nn.Module): |
PSPnet
Motivation
关注到 FCN 在做分割的时候,实际上会把一些很相近的东西(比如 car 和 boat)给错误分割了。并且还会把一些大块的建筑物中间给错误分割。这样的问题在于对象的外观相似,并且以 car 和 boat 的案例思考,这样的分割我们应当参考周边的元素,而这是 FCN 没有关注到的。
作者通过观察 baseline 在 ADE20K 数据集上得出的实验结果考虑以下问题:
- 上下文匹配错误,也就是在分辨具体的物体的时候没有参考周围的信息。
- 相似label 的匹配错误,比如 building 和 skyscraper 这两个label 是很相似的,但是 FCN 会在这种情况下二者互相混淆,导致同一个建筑物里的标签出现啥都有的情况。
- 小物品丢失:比如床上的枕头,路灯这些小尺度的物品很难被发现。同时也有一些巨大的物品超出感受野范围导致不连续预测。
Methods
PSPnet 最大的贡献是提出了金字塔型池化结构(Pyramid Pooling Module)
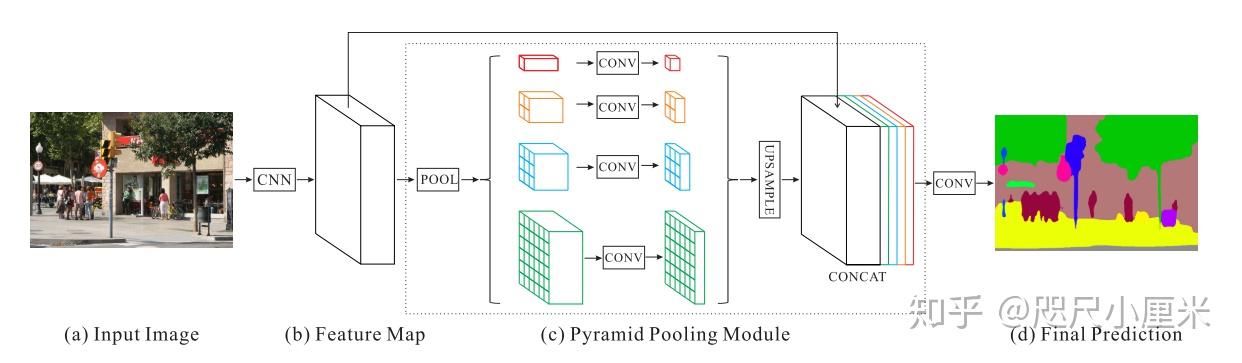
不同层次的feature map在平滑和拼接之后被用于图像分类。这种先验信息是为了消除了CNN中固定尺寸的约束。为了进一步减少不同子区域之间的上下文信息丢失,我们提出了一种分层的全局先验信息,其中包含具有不同尺寸和在不同子区域之间变化的信息。这被称为Pyramid Pooling Module。其实本质上是用多个卷积核来获取不同粒度的上下文信息。

(a)->(b) 的部分的 CNN 采用了 ResNet 作为 backbone,并且卷积核部分使用了空洞卷积。空洞卷积的话是,在原本的卷积核填充 0 或者在输入里等间隔采样,可以看下图:
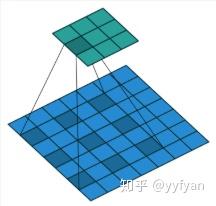
主要就是扩大感受野,而他比 downscale 的作用在于降低了计算量,而且不会丢失分辨率,就是说我依然能返回精确的像素,在分割里面是更有用的。同时空洞卷积有一个参数 dilation rate,设置不同的时候感受野就不一样,也就获取了多尺度信息,在视觉任务中相当重要。
记 $r$ 为 dilation rate,$k$ 为原始的卷积核大小,那么感受野 $K$ 为:
$$
K = k + (k-1)(r-1)
$$
分割领域泛读(FCN,Unet)