Vision Transformer(ViT)学习笔记
ViT $\not=$ Vitality
ViT = Vision Transformer
学长推荐 3/20
Motivation
当 Transformer 架构在 NLP 领域大获成功,在当时(2020 年)卷积结构仍然占据主导地位。之前的工作尝试把 attention 机制和 CNNs 结合起来,这篇文章尝试了以最小的改动把标准 Transformer 用于图像处理。
Methods
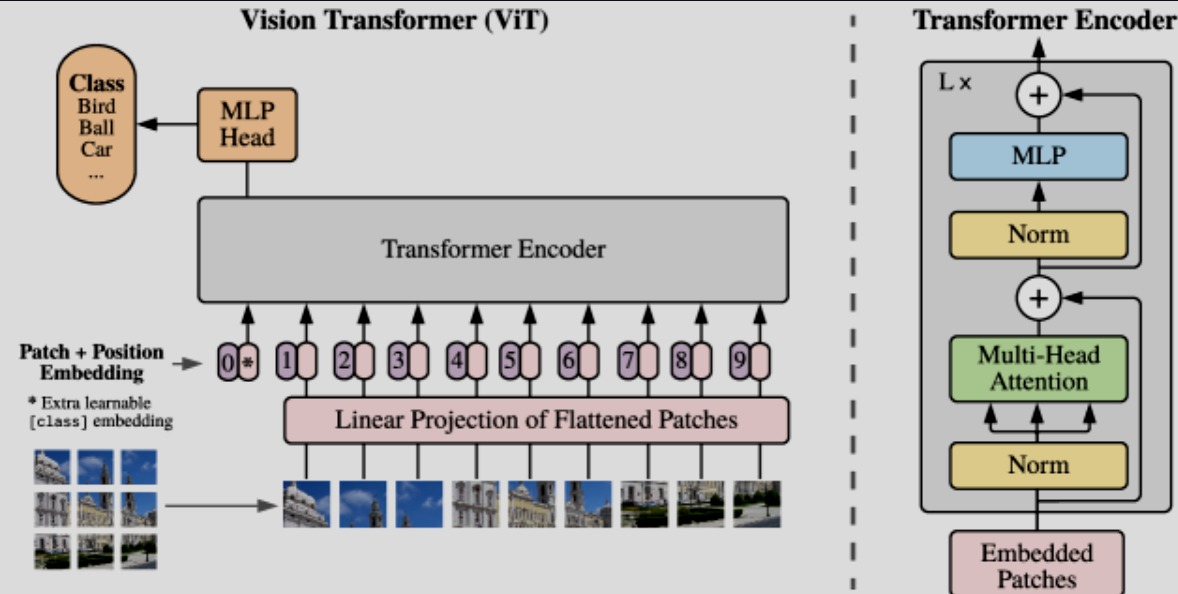
为了直接调用开箱即用的 Transformer 模型,作者考虑把一张 $(H,W,C)$ 的图像变成一堆展平的图像块 $N\times(P^2,C)$,其中 $N = HW / P^2$,也就是 Transformer 的有效输入序列长度。为了把图像信息转变成 Transformer 需要的 d_model size, ViT 先把图像块展平,然后用一个可以训练的线性投影层变成 D 维度(这个投影层会根据反向传播优化学习)。也就是下公式:
$$
𝐳
0
[
𝐱
_{
class}
;
𝐱
p
1
𝐄
;
𝐱
p
2
𝐄
;
⋯
;
𝐱
p
N
𝐄
]
+
𝐄
p
o
s
,
𝐄
∈
ℝ
(
P
2
⋅
C
)
×
D
,
𝐄
p
o
s
∈
ℝ
(
N
+
1
)
×
D
$$
ViT同样需要加入位置编码,为了进行分类,此处额外引入了一个可以学习的标记,这里和 BERT 里的 [class] token 是一个东西,在每个token 前面加上了一部分分类头,最后分类就是看这个唯一分类的头。在预训练的时候,这个就是一个MLP,finetune的时候只需要一个线性层就可以了。
位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是
从归纳偏置的角度上来说,ViT 的归纳偏置对比 CNN 来说更小,换句话说就是 CNN 更加关心图像的具体结构,ViT 只有在 MLP 层会使用到图像的二维特性,剩下的时刻都是用的一维特性。也就让 ViT 具有了更高的灵活性和潜力。不过也是因为这,后面有了 Swin-T 来带回归纳偏置,使得更加有道理。
并且作者提到,可以使用混合架构,也就是说输入部分可以直接使用 CNN 出来的结果,embedding可以直接展平到投影维度即可。
对于微调任务,实际任务上移除掉前面的预测头,然后加上一个 $D \times K $ 的前馈层。而且当使用高分辨率的时候,会增加 patch 的个数,所以原来我们学习到的位置嵌入就需要进行二维插值。
Experiments
作者选用了 ResNet, ViT 以及混合模型作对比,在 ImageNet-21k 上先进行了大规模的与训练,并且迁移到了几个小的训练集上。类似 BERT, ViT 同样设计了 Base,Large和Huge 三个版本的模型。
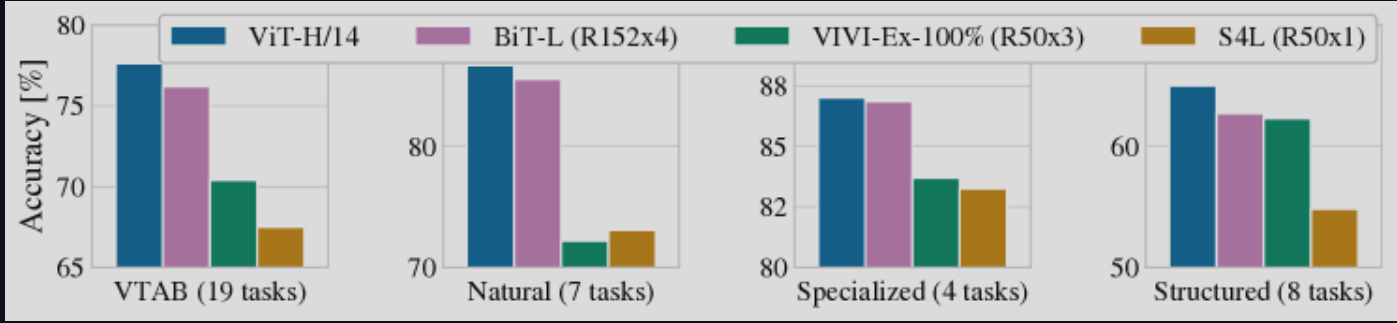
作者还探索了数据集规模的重要性: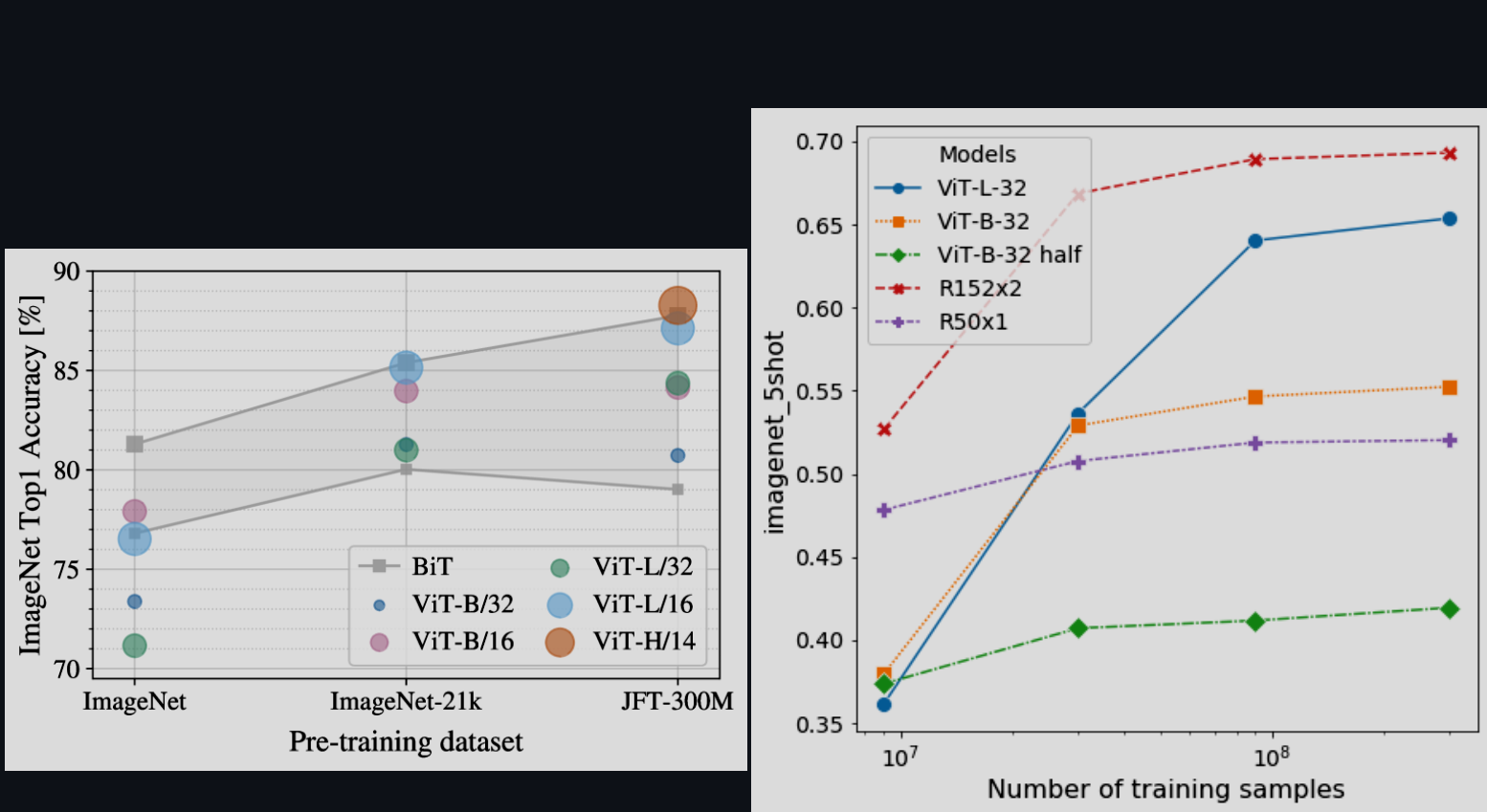
在较小的数据集上,ViT 比具有相当计算成本的 ResNet 更容易过拟合。其次,在较小的计算预算下,混合模型的表现略优于ViT,但随着模型规模的增大,这种差异逐渐消失。这一结果有些出乎意料,因为人们通常会认为无论模型规模如何,卷积局部特征处理都应该有助于提升ViT的表现。
最重要的一点:VIT在所尝试的范围内似乎并未达到饱和状态,这为未来的规模扩展研究提供了动力。也就是为什么 ViT 开创了Transformer 在 CV 领域应用。
Vision Transformer(ViT)学习笔记