ViT-Adapter 学习笔记
学长推荐 (6/20)
Motivation
近年来对于 ViT 的探索分两类,一类是原始的 ViT,一类是类金字塔模型(如 Swin-T),后者证明了保留一些归纳偏置会在密集预测任务(如分割上)带来更好的效果。但是之前的研究问题是,对于多模态的效果可能不如朴素的 ViT。所以本文提出了 ViT-adapter 和三个模块。
Features
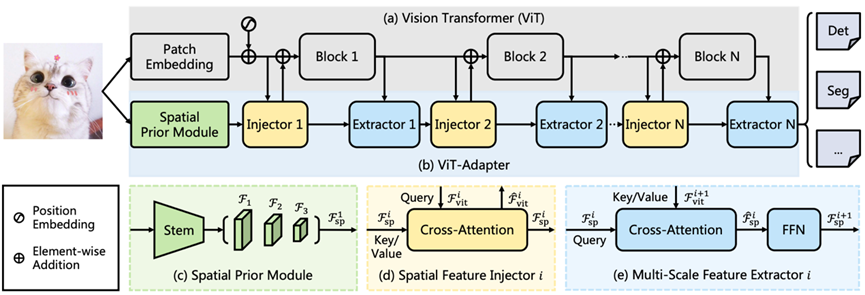
ViT-Adapter 分成两个模块,上层是正常的 ViT,下层是带有 Spatial Prior Module 和 Injector,Extractor 的一个 adapter.
Spatial Prior Module
(参见上图 (c) )有研究表明卷积层可以更好地给 Transformer 提供信息,所以通过卷积,我们得到了 1/8,1/16 和 1/32 的特征金字塔,然后展平拼接之后就得到先验特征。因为他和 Patch Embedding 是同时进行的,所以也就不会对原本的模块造成影响。
Spatial Feature Injector
这部分是一个交叉注意力结构,这部分的关键在于把 ViT 原本的输入特征 $F_{vit}^i$ 当作 $Q$,利用我们在 Spatial Prior Module 得到的空间先验信息,通过交叉注意力得到 $\hat{F}^i_{vit}$ 也就把多的信息给带进去了,公式为:
$$
\hat{\mathcal{F}}^{i}{\text{vit}}=\mathcal{F}^{i}{\text{vit}}+\gamma^{i} \text{Attention}(\text{norm}(\mathcal{F}^{i}{\text{vit}}),\text{norm}( \mathcal{F}^{i}{\text{sp}})),
$$
接下来就是,把 $\hat{\mathcal{F}}^{i}_{\text{vit}}$ 的信息代入到 ViT 中,相当于把Spatial 的信息给融合到 ViT 里了。
Multi-Scale Feature Extractor
这部分是一个从 ViT 中提取信息,然后应用 FFN 和交叉注意力提取出新的层次的信息。也就是:
$$
F^{i+1}{sp} = \hat{F}^i{sp} + FFN(Norm(\hat{F}^i_{sp})) \
\hat{F}^i_{sp} = F^i_{sp} + Attention(Norm(F_{sp}^i),Norm(F_{vit}^{i+1}))
$$
这里使用的是稀疏注意力。
ViT-Adapter 学习笔记