mask2former
detr
关于分割问题,我们有两个核心思想:
- 逐个像素去分割(per-pixel classification)
- 先通过一些方法获得 mask,然后直接对mask做classification(mask classification)
这个框架我只做了一个大致的了解,据说是第一个用 transformer 实现目标检测的框架。整体思想比较简单,产生一堆候选框:
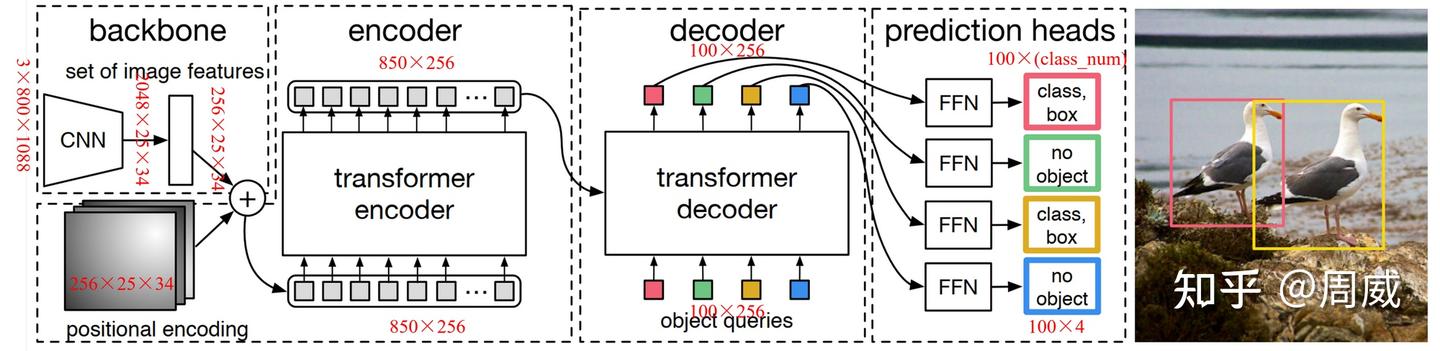
- 输入图像用 CNN 映射为特征图,然后用一个1x1卷积层降维到 $256\times \frac{H}{32}\times \frac{W}{32}$ ,生成一个对应大小的位置编码并且直接按位相加。reshape 成 $N\times 256(N = \frac{HW}{32\times 32})$
- 把特征图输入进 Transformer 中,这里我们构建一个 $100 \times 256$ 的object queries,这是一个可学习的编码,100 的是为了告诉模型至多产生 100 个物体区域。学习之后这个东西的作用是告诉 encoder 哪些区域可能有物体。接下来,把 object queries 和编码器的特征图喂给 transformer.
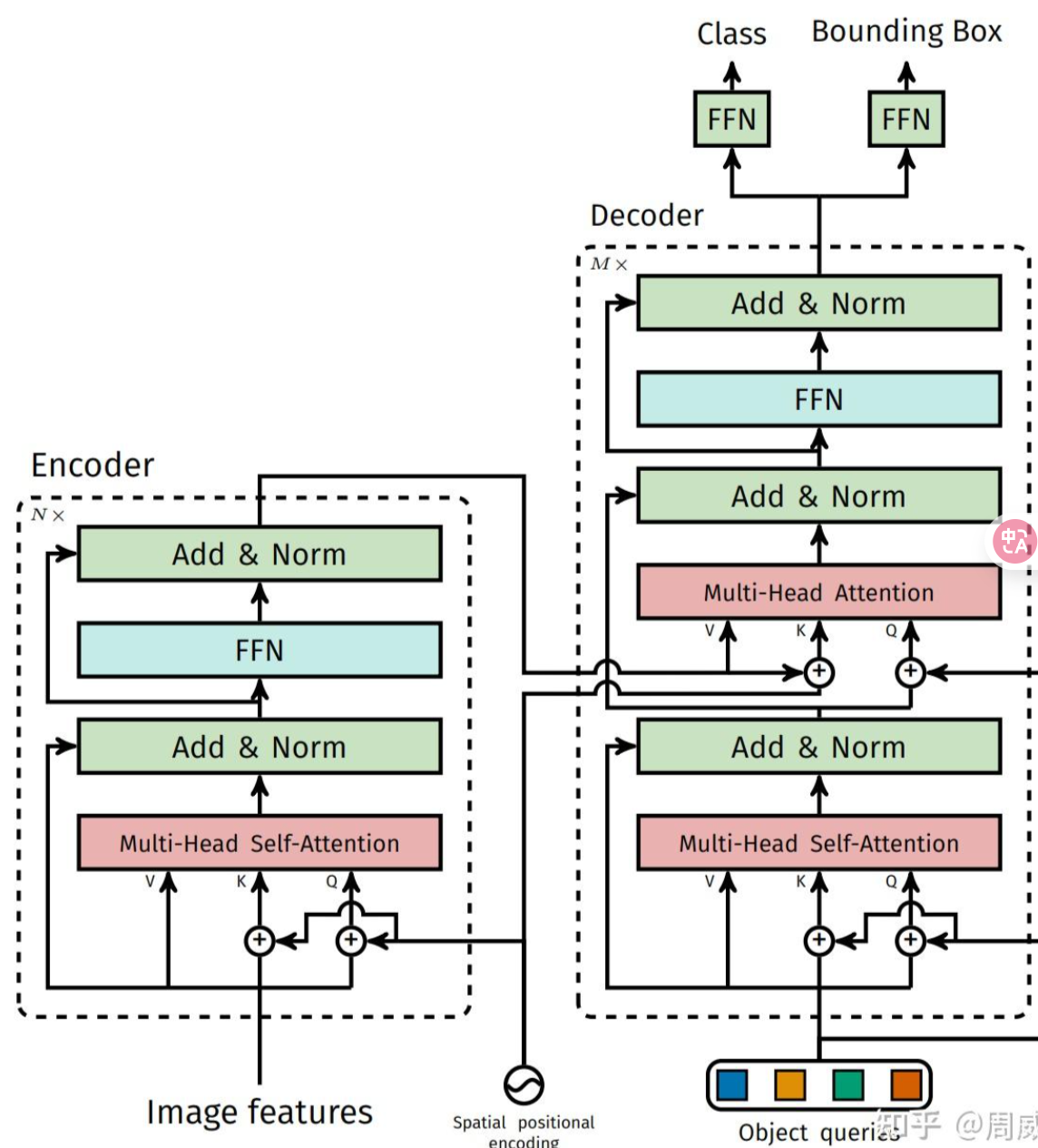 把 object queries作为decoder第一层多头注意力的输入,图像特征作为 encoder 第一层多头自注意力的输入
把 object queries作为decoder第一层多头注意力的输入,图像特征作为 encoder 第一层多头自注意力的输入 - 对输出的区域集合和真实的标签,利用匈牙利算法跑二分图匹配,计算二者的相似度,这个作为 loss
- 反向更新 CNN 和 transformer 。
值得一提的是,object queries 每个框和大小都有区别,因为他是自己学习出来的,就是作用有点像 anchor 但是又不完全像.
然后这个二分图匹配具体是怎么跑的:构造一个北京类,把他补充道图像的标签中,现在对于两个集合:预测集和标签集,然后定义两个元素之间的 cost 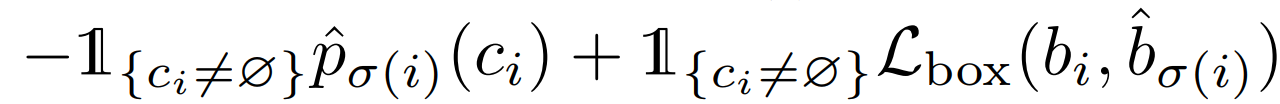
接下来就是用二分图匹配的一个过程了。
maskformer
maskformer 的结构更好理解,他把任务分成两部分:第一部分是从 feature -> mask,第二部分是从 mask -> classification。我们分两步理解:
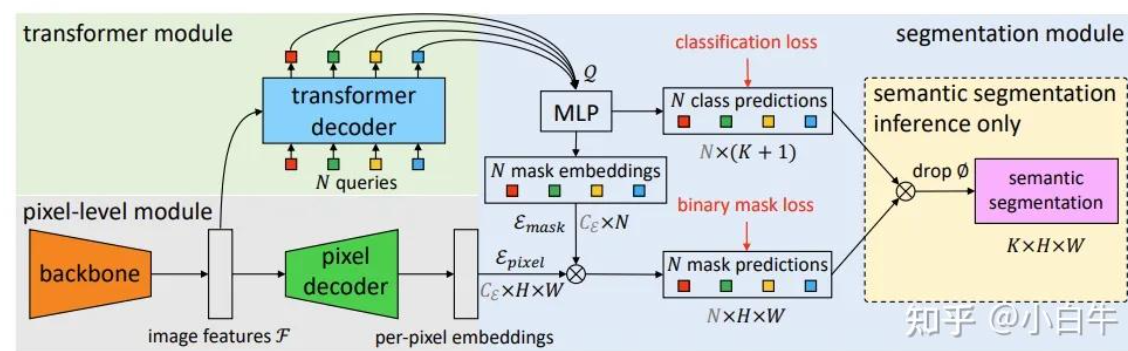
第一步和 detr 一样,同样通过 backbone 的 CNN 网络获得图像特征。接下来 feature 直接进入 transformer decoder,类似 detr,通过 n 个 queries 获得 embedding 信息,这里用 Q 表示。 Q 代表的是每个mask 的全局 feature 信息,但是我这个时候不知道每个像素的信息,还需要后续处理。
通过 pixel decoder 把 feature 还原到像素级别,获得 per-pixel embeddings,把 Q 通过 MLP 对齐到像素的维度,通过对这两个 feature 进行点积,获得的是 pixel 维度下的 mask信息。
第二步,我们知道 Q 指代了 mask 的全局 feature 信息,我们直接给他加一个 classification 的 head获得了 class prediction,这里就是给每个 mask 分配了一个 class 信息,并计算 classification loss。
Mask2Former
mask2former 对 maskformer 做出了几个调整: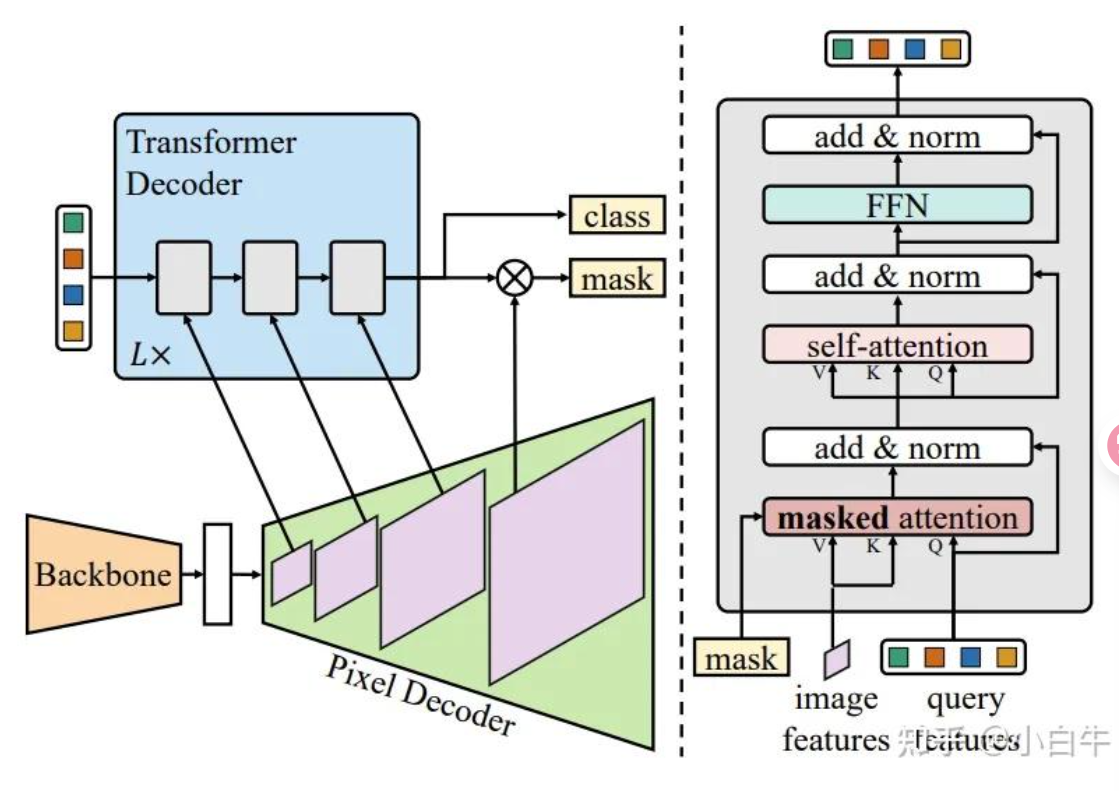
在原本的 decoder 里面,我们做 attention 实际上是对整个 features 做 attention。现在我们通过把他转化为局部问题,用 masked attention 变成旨在一个区域里做 attention。具体来说,我们把 attention 的公式变成:
$$
X_l = \text{softmax}(\text{M}{l-1},Q_lK_l^T)V_l + X{l-1} \
\text{M}{l-1}(x,y) = M{l-1}(x,y) = 1 ? 0 : -\inf
$$
这个 $M$ 来自上一层预测的结果,他是一个 $H\times W$ 的01矩阵。本质上就是一个迭代,每一层的 masked attention 都是来自上一层的 transformer module.
第二部是在 pixel decoder 里面引入了标准的特征金字塔思想,把不同尺度的 feature 给 transformer 作为 KV 一直做 attention。我们一共做 $L$ 次,那么其实一共有 $3L$ 个 transformer 层,一直以 $\frac{1}{32},\frac{1}{16},\frac{1}{8}$ 的尺寸来回循环。
在优化方面,transformer里面把 self-attention 和 crossattention 的顺序交换,我们将查询特征也设为可学习的(我们仍然保留可学习的查询位置嵌入),并在这些可学习的查询特征用于Transformer解码器预测掩码之前对其进行直接监督。
mask2former