SegFormer
学长推荐(12/20)
Motivation
感觉这个东西其实考虑是从 SETR 的问题里面改过来,然后出来一个新的东西。因为 SETR 很多想法是来自于 ViT,但是 ViT 实际上是不太好做分割的,所以我们就要重新设计 Encoder 和 Decoder。
Methods
从 Encoder 的角度入手,回顾一下 U-net 等经典的分割模型,他们很多都是输出高低分辨率的特征,为了保证特征既有细粒度也有粗粒度。这也让像素分类更准、边缘细节分割效果更加精细。本文重新设计了 Transformer encoder:每个patch 设计成有 overlap 的,保证局部连续性,并且在 FFN 离引入 3x3 的 dwconv 传递位置信息。
其实我没看懂overlap,拼尽全力无法理解。
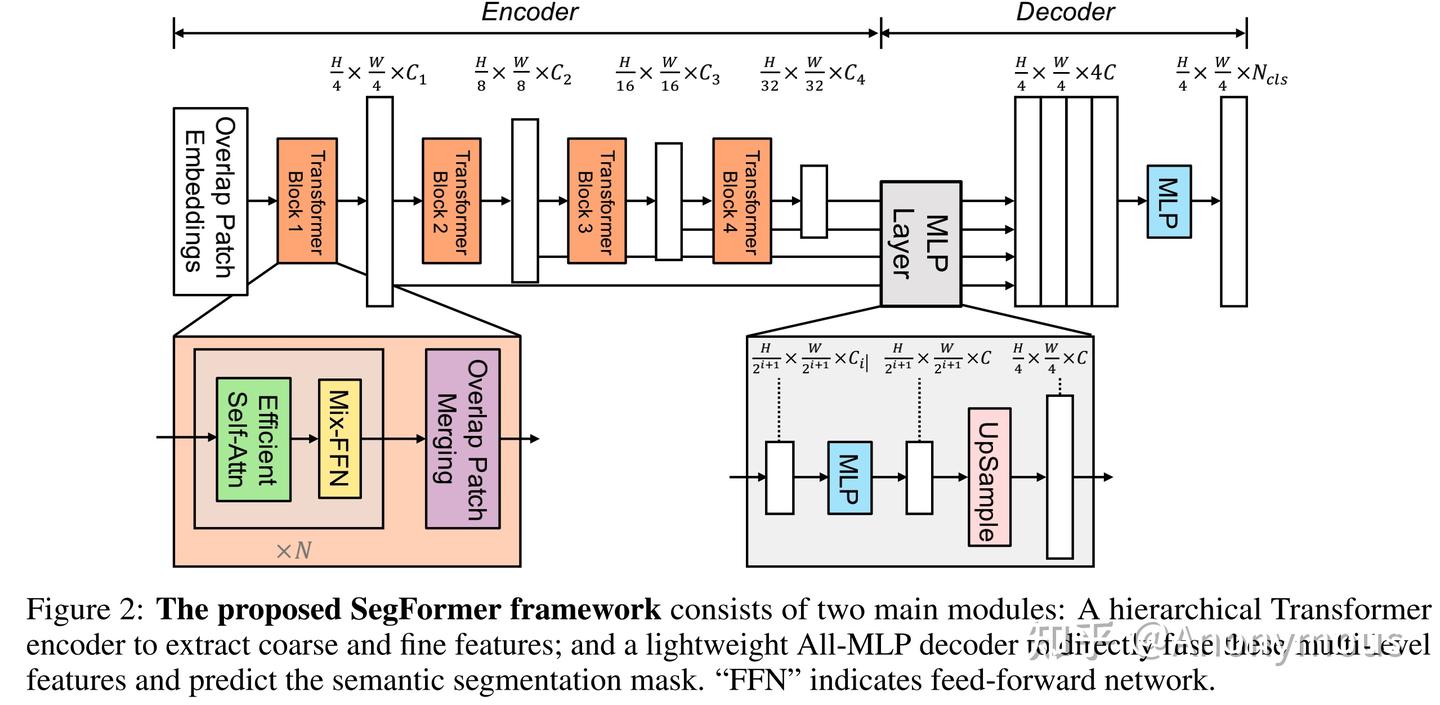


对于 Decoder,直接采用了更加简单的方法:就是直接使用了若干个 MLP 层,首先对所有层的 feature 分别过一个 linear 层融合,然后 upsample 完 concat,最后一个linear层融合然后预测结果。这里的原因其实是因为 Transformer 天然有巨大的感受野,不同于 CNN 类的网络。
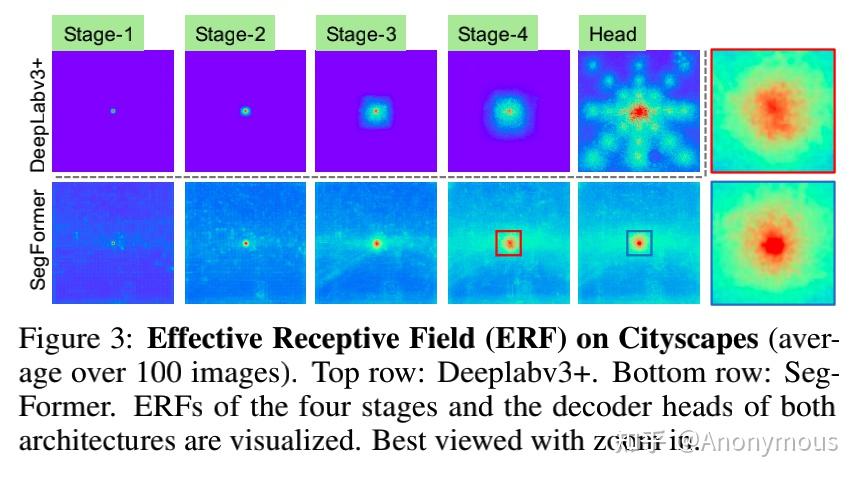
这里的话,和 SETR 在 decoder 部分做不同分辨率来说更加优雅一点,因为我总觉得直接抽出几个层来做会在decoder层很暴力,并且这也让decoder层变得很复杂。这里就是相当于把多个尺寸的获取信息工作给了不同的transformer模块去做。
SegFormer